

How to Fine-Tune DeepSeek R1 Using LoRA
如何使用 LoRA 微调 DeepSeek R1
This guide walks through fine-tuning DeepSeek R1 using LoRA, a Parameter-Efficient Fine-Tuning (PEFT) method that updates only a small portion of model parameters to improve function calling. It covers dataset preparation, model configuration, and training using Hugging Face tools, making fine-tuning efficient and resource-friendly. The result is a model that performs function calls accurately following the dataset design.
本指南介绍如何使用 LoRA 对 DeepSeek R1 进行微调,LoRA 是一种参数高效微调 (PEFT) 方法,仅更新一小部分模型参数以改进函数调用。它涵盖了数据集准备、模型配置和使用 Hugging Face 工具进行训练,使微调变得高效且资源友好。结果是一个按照数据集设计准确执行函数调用的模型。
DeepSeek is quickly gaining attention for its impressive performance and cost efficiency, so I decided to write about fine-tuning it. In this post, we’ll work with a smaller DeepSeek model and demonstrate how to apply supervised fine-tuning (SFT) using a Parameter-Efficient Fine-Tuning (PEFT) approach via Low-Rank Adaptation (LoRA). We’ll be fine-tuning the model on a function calling dataset, showing how you can quickly and efficiently adapt large language models (LLMs) to improve their function calling capabilities. With this pipeline, you can easily swap out the dataset or model to fine-tune models on specific domains.
DeepSeek 因其令人印象深刻的性能和成本效益而迅速受到关注,因此我决定写一篇关于微调它的文章。在本文中,我们将使用一个较小的 DeepSeek 模型,并演示如何通过低秩自适应 (LoRA) 使用参数高效微调 (PEFT) 方法应用监督微调 (SFT)。我们将在函数调用数据集上微调模型,展示如何快速有效地调整大型语言模型 (LLM) 以改进其函数调用功能。使用此管道,您可以轻松换出数据集或模型,以微调特定域上的模型。
What is Parameter-Efficient Fine-Tuning (PEFT) and LoRA?
什么是参数高效微调 (PEFT) 和 LoRA?
Full fine-tuning of LLMs can be resource intensive. PEFT techniques, such as LoRA, offer an elegant solution by adjusting only a small subset of parameters. LoRA works by freezing the model’s weights and injecting trainable, low-rank matrices into key layers.
对 LLM 进行全面微调可能会占用大量资源。PEFT 技术(如 LoRA)通过仅调整一小部分参数来提供优雅的解决方案。LoRA 的工作原理是冻结模型的权重,并将可训练的低秩矩阵注入关键层。
Consider a weight matrix ( W ) in a Transformer layer. Instead of updating ( W ) directly, we update it as:
考虑 Transformer 层中的权重矩阵 ( W )。我们不是直接更新 ( W ),而是将其更新为:
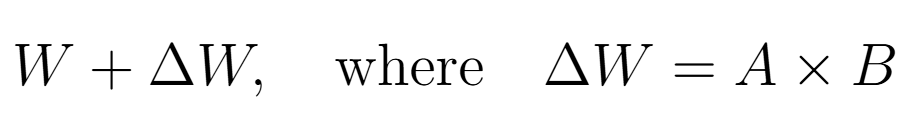
Here, ( A ) and ( B ) are low-rank matrices which are the trainable weights being injected. In practice, you define a rank r so that ( A ) has shape (N, r) and ( B ) has shape (r, M), the multiplication results in a matrix with the same shape a (W) (N, M). Experiments have shown that values such as r=8, r=16, or r=32 often achieve excellent performance comparable to a full fine-tuning, while only training ~1% of the total parameters.
这里,( A ) 和 ( B ) 是低秩矩阵,它们是要注入的可训练权重。在实践中,您定义一个秩,即 ( A ) 具有形状 (N, r) 和 ( B ) 具有形状 (r, M),乘法得到具有相同形状 a (W)(N, M) 的矩阵。实验表明,诸如 r=8、r=16、orr=32 等值通常可以获得与完全微调相当的出色性能,而仅训练总参数的 ~1%。
Hands-On: Fine-Tuning DeepSeek with LoRA 动手实践:使用 LoRA 微调 DeepSeek
In this section, we’ll walk through the process of fine-tuning a DeepSeek model on a function calling dataset using LoRA.
在本节中,我们将演练使用 LoRA 在函数调用数据集上微调 DeepSeek 模型的过程。
1. Setting Up Your Environment 1. 设置您的环境
I’ve been using the official Hugging Face Docker image (huggingface/transformers-pytorch-gpu) with Jupyter Notebook locally. You’ll need to install the necessary libraries with:
我一直在本地将官方的 Hugging Face Docker 镜像 ()huggingface/transformers-pytorch-gpu 与 Jupyter Notebook 一起使用。您需要使用以下命令安装必要的库:
pip install transformers datasets accelerate evaluate bitsandbytes peft trl wandb optimum**2. Preparing the Function Calling Dataset
2. 准备函数调用 dataset**
We will use the glaiveai/glaive-function-calling-v2 dataset. Since the raw dataset contains chat interactions not leading to function calling, we first filter the data and later we’ll balance the samples.
我们将使用数据集glaiveai/glaive-function-calling-v2。由于原始数据集包含不会导致函数调用的聊天交互,因此我们首先筛选数据,然后平衡样本。
**2.1. Load and Filter the Dataset
2.1. 加载和过滤数据集**
import multiprocessing
from datasets import load_dataset
max_seq_length = 512
dataset_size = 'small'
train_eval_split = 0.1
train_test_split = 0.01
seed = 42
dataset_path = 'glaiveai/glaive-function-calling-v2'
fn_calling_dataset = load_dataset(
dataset_path, split='train',
num_proc=multiprocessing.cpu_count()
)
# Select samples that contain either a function call or a message indicating inability to call a function.
dataset_reduced = fn_calling_dataset.filter(
lambda x: "I'm sorry" in x["chat"] or "functioncall" in x["chat"]
).shuffle(seed=seed)
dataset_reduced>>> Dataset({
>>> features: ['system', 'chat'],
>>> num_rows: 78392
>>> })We now “balance” the dataset to include both cases — when a function call is found and not — and then split it into training and testing sets. This will help us balance the dataset between the scenarios we want the model to improve:
现在,我们“平衡”数据集以包括这两种情况(当找到函数调用时,未找到函数调用时),然后将其拆分为训练集和测试集。这将帮助我们在希望模型改进的场景之间平衡数据集:
- Knowing when it can’t do a function call;
知道何时无法执行函数调用; - How to perform a function call when it can.
如何在可以执行函数调用时执行函数调用。
from datasets import concatenate_datasets
def get_dataset_size(dataset_size):
if dataset_size == "small":
missed_amount = 200
found_amount = 600
elif dataset_size == "medium":
missed_amount = 350
found_amount = 750
elif dataset_size == "large":
missed_amount = 375
found_amount = 825
return missed_amount, found_amount
# Reserve a portion of the data for testing.
test_amount = max(int(train_test_split * dataset_reduced.num_rows), 25)
dataset_reduced_train = dataset_reduced.select(range(dataset_reduced.num_rows - test_amount))
# Determine the number of samples for each scenario.
missed_amount, found_amount = get_dataset_size(dataset_size)
dataset_train_missed = dataset_reduced_train.filter(
lambda x: "I'm sorry" in x["chat"] and not ("functioncall" in x["chat"])
).select(range(missed_amount))
dataset_train_found = dataset_reduced_train.filter(
lambda x: not ("I'm sorry" in x["chat"]) and "functioncall" in x["chat"]
).select(range(found_amount))
# Concatenate the two balanced datasets.
dataset_final_train = concatenate_datasets([dataset_train_missed, dataset_train_found])
# The reduced dataset now contains a small balanced mix of samples
dataset_final_train>>> Filter: 100%|██████████| 77609/77609 [00:00<00:00, 95166.57 examples/s]
>>> Filter: 100%|██████████| 77609/77609 [00:00<00:00, 105422.00 examples/s]
>>> Dataset({
>>> features: ['system', 'chat'],
>>> num_rows: 800
>>> })2.2. Converting the Dataset Format 2.2. 转换数据集格式
We’ll be using the TRL library to handle a couple of steps, such as input tokenization, so we need to transform the dataset samples into a format the TRL trainer class expects.
我们将使用 来处理TRL library几个步骤,例如输入标记化,因此我们需要将数据集样本转换为 TRL trainer 类所需的格式。
The dataset contains system and chat entries. For example, a sample from the dataset looks like:
数据集包含 systemandchatentries。例如,数据集中的样本如下所示:
>>> SYSTEM: You are a helpful assistant with access to the following functions. Use them if required -
{
"name": "convert_currency",
"description": "Convert the amount from one currency to another",
...
}
-----
USER: Hi, I need to convert 500 US dollars to Euros. Can you help me with that?
ASSISTANT: {"name": "convert_currency", "arguments": '{"amount": 500, "from_currency": "USD", "to_currency": "EUR"}'}
FUNCTION RESPONSE: {"converted_amount": 425.50, ...}
ASSISTANT: Sure, 500 US dollars is approximately 425.50 Euros.We convert the original format (with system and chat fields) into a list messages:
我们将原始格式 (withsystemandchatfields) 转换为 listmessages:
import re
from typing import List, Any, Dict, Tuple
def chat_str_to_messages(chat_str: str) -> Dict[str, Tuple[str, str]]:
try:
# Limit the chat to the point before the first function response.
chat_until_function_call = chat_str[: next(re.finditer(r"FUNCTION\sRESPONSE\:", chat_str)).start()].strip()
except StopIteration:
chat_until_function_call = chat_str.strip()
# use regex to find all user and assistant messages.
matches = re.findall(
r"(USER|ASSISTANT):\s(.*?)(?=\n\n|$)", chat_until_function_call, re.DOTALL
)
chat_interaction = [
(matchh[0], matchh[1].replace(" <|endoftext|>", "").strip())
for matchh in matches
]
return chat_interaction
def transform_dataset_format(data_from_sample: List[Any]) -> Dict[str, List[Dict[str, str]]]:
texts = []
system_prompts = list(map(lambda x: re.split(r"SYSTEM\:\s", x)[1].strip(), data_from_sample["system"]))
chats = list(map(chat_str_to_messages, data_from_sample["chat"]))
for systemprompt, chatnow in zip(system_prompts, chats):
messages = [{"role": "system", "content": systemprompt}] + [
{"role": role.lower(), "content": msg} for role, msg in chatnow
]
texts.append(messages)
return {"messages": texts}
dataset_train = dataset_final_train.map(
transform_dataset_format, batched=True,
remove_columns=dataset_final_train.column_names,
)
dataset_train>>> Map: 100%|██████████| 800/800 [00:00<00:00, 24218.98 examples/s]
>>> Dataset({
>>> features: ['messages'],
>>> num_rows: 800
>>> })Now, we inspect a sample to ensure the format is correct:
现在,我们检查样本以确保格式正确:
>>> {'messages': [{'content': 'You are a helpful assistant with access to the following functions. Use them if required -\n{\n "name": "calculate_distance",\n "description": "Calculate the distance between two locations",\n "parameters": {\n "type": "object",\n "properties": {\n "start_location": {\n "type": "string",\n "description": "The starting location"\n },\n "end_location": {\n "type": "string",\n "description": "The ending location"\n }\n },\n "required": [\n "start_location",\n "end_location"\n ]\n }\n}', 'role': 'system'}, {'content': 'Can you please book a flight for me from New York to Los Angeles?', 'role': 'user'}, {'content': "I'm sorry, but as an AI, I don't have the capability to book flights. My current function allows me to calculate the distance between two locations. If you need to know the distance between New York and Los Angeles, I can certainly help with that.", 'role': 'assistant'}]}Finally, we split the dataset between training and validation:
最后,我们将数据集分为训练和验证:
dataset_train_eval= dataset_train.train_test_split(test_size=train_eval_split)
dataset_train_eval>>> DatasetDict({
>>> train: Dataset({
>>> features: ['messages'],
>>> num_rows: 720
>>> })
>>> test: Dataset({
>>> features: ['messages'],
>>> num_rows: 80
>>> })
>>> })**3. Loading the Pre-Trained DeepSeek Model and Configuring LoRA
3. 加载预先训练的 DeepSeek 模型并配置 LoRA**
Now that the dataset is ready, we load the DeepSeek model, set up the LoRA configuration, and let the GPU burn! Let’s check the amount of trainable parameters.
现在数据集已经准备好了,我们加载 DeepSeek 模型,设置 LoRA 配置,然后让 GPU 刻录!我们来检查一下可训练参数的数量。
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = 'deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B'
model_size = '1.5B'
lora_r = 4 # this will vary the amount of trainable parameters - it's correlated with the performance gains.
lora_alpha = 16 # according to the paper, this is the best value for most tasks.
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj"] # Modules to apply LoRA - it's correlated with the amount of trainable parameters.
# Load model and tokenizer.
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(
model_name, padding=True, truncation=True, max_length=max_seq_length
)
# Set up the LoRA configuration.
lora_config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
lora_dropout=0.1,
target_modules=target_modules,
init_lora_weights="gaussian",
task_type="CAUSAL_LM",
inference_mode=False
)
# Wrap the model with LoRA and check the amount of trainable parameters
peft_model = get_peft_model(model, lora_config)
peft_model.print_trainable_parameters()>>> trainable params: 1,189,888 || all params: 1,778,277,888 || trainable%: 0.06694. Configuring and Running the Fine-Tuning Process
4. 配置并运行微调过程**
4.1. Customizing Trainer Class 4.1. 自定义 Trainer 类**
Using the TRL library, we set up a simple supervised fine-tuning trainer. I extended the original SFTTrainer class to ensure that the tokenizer properly handles padding to the specified max_seq_length. Not sure if there’s an issue when tokenizing with padding, but the SFTTrainer class seems to ignore the configuration to add max_seq_length padding to input.
使用 TRL 库,我们设置了一个简单的监督式微调训练器。我扩展了 originalSFTTrainer类,以确保分词器正确处理specifiedmax\_seq\_length的填充。不确定使用填充进行标记化时是否存在问题,但是SFTTrainer类似乎忽略了addmax\_seq\_lengthpadding输入的配置。
import warnings
from datasets import Dataset
from typing import Optional, Callable
from trl import SFTTrainer
class CustomSFTTrainer(SFTTrainer):
def _prepare_non_packed_dataloader(
self,
processing_class,
dataset,
dataset_text_field: str,
max_seq_length,
formatting_func: Optional[Callable] = None,
add_special_tokens=True,
remove_unused_columns=True,
):
# Inspired from: https://huggingface.co/learn/nlp-course/chapter7/6?fw=pt
def tokenize(element):
outputs = processing_class(
element[dataset_text_field] if formatting_func is None else formatting_func(element),
add_special_tokens=add_special_tokens,
truncation=True,
padding="max_length",
max_length=max_seq_length,
return_overflowing_tokens=False,
return_length=False,
)
if formatting_func is not None and not isinstance(formatting_func(element), list):
raise ValueError(
"The `formatting_func` should return a list of processed strings since it can lead to silent bugs."
)
return {"input_ids": outputs["input_ids"], "attention_mask": outputs["attention_mask"]}
signature_columns = ["input_ids", "labels", "attention_mask"]
if dataset.column_names is not None: # None for IterableDataset
extra_columns = list(set(dataset.column_names) - set(signature_columns))
else:
extra_columns = []
if not remove_unused_columns and len(extra_columns) > 0:
warnings.warn(
"You passed `remove_unused_columns=False` on a non-packed dataset. This might create some issues with "
"the default collator and yield to errors. If you want to inspect dataset other columns (in this "
f"case {extra_columns}), you can subclass `DataCollatorForLanguageModeling` in case you used the "
"default collator and create your own data collator in order to inspect the unused dataset columns.",
UserWarning,
)
map_kwargs = {
"batched": True,
"remove_columns": dataset.column_names if remove_unused_columns else None,
"batch_size": self.dataset_batch_size,
}
if isinstance(dataset, Dataset):
map_kwargs["num_proc"] = self.dataset_num_proc # this arg is not available for IterableDataset
tokenized_dataset = dataset.map(tokenize, **map_kwargs)
return tokenized_dataset4.2. Running the Trainer 4.2. 运行 Trainer
There are a couple of parameters that have an impact on time/resources used during training, and it will depend on the type of hardware you are running. Newer GPUs would allow you to cast the model to torch.bfloat16, use tf32 dtype during training, etc, which would greatly improve training speed and GPU usage. This setup allows you to run with Google Colab’s free T4 GPU. You can also control the memory usage by configuring per_device_train_batch_size and gradient_accumulation_steps as the batch size is given by per_device_train_batch_size * gradient_accumulation_steps.
有几个参数会影响训练期间使用的时间 / 资源,具体取决于您运行的硬件类型。较新的 GPU 将允许您在训练期间将模型转换为 torch.bfloat16、usetf32dtype 等,这将大大提高训练速度和 GPU 使用率。此设置允许您使用 Google Colab 的免费 T4 GPU 运行。您还可以通过configuringper\_device\_train\_batch\_sizeandgradient\_accumulation\_stepsas批处理大小指定为 byper\_device\_train\_batch\_size * gradient\_accumulation\_steps来控制内存使用。
import pathlib
import wandb
import os
from trl import SFTConfig
num_train_epochs = 1
max_steps = 200
bf16 = False
output_dir = 'results'
run_name = f"{model_name.split('/')[-1]}-fncall_peft-ds_{dataset_size}-lora_r_{lora_r}-use_qlora_False"
output_dir_final = os.path.join(output_dir, run_name)
# Adjust tokenizer settings as warned by the trainer
tokenizer.padding_side = 'right'
# Log into wandb.
wandb.login(os.environ.get("WANDB_API_KEY"))
print("Creating trainer...")
pathlib.Path(output_dir_final).mkdir(parents=True, exist_ok=True)
training_args = SFTConfig(
dataset_text_field="messages",
num_train_epochs=num_train_epochs,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=8,
gradient_checkpointing=True, # Saves memory at the cost of additional training time.
bf16=bf16,
tf32=False, # use tf32 for faster training on Ampere GPUs or newer.
dataloader_pin_memory=False, # pin data to memory.
torch_compile=False, # compile to create graphs from existing PyTorch programs.
warmup_steps=50,
max_steps=max_steps,
learning_rate=1e-4,
lr_scheduler_type="cosine",
weight_decay=0.01,
logging_strategy="steps",
save_strategy="steps",
save_steps=50,
save_total_limit=3,
eval_strategy="steps",
logging_steps=10,
output_dir=output_dir_final,
optim="paged_adamw_8bit",
remove_unused_columns=True,
seed=seed,
run_name=run_name,
report_to="wandb",
push_to_hub=False,
eval_steps=25,
)
trainer = CustomSFTTrainer(
model=model,
args=training_args,
train_dataset=dataset_train_eval["train"],
eval_dataset=dataset_train_eval["test"],
processing_class=tokenizer,
peft_config=lora_config
)
print("Training...")
trainer.train()>>> Training...
>>> wandb: Using wandb-core as the SDK backend. Please refer to https://wandb.me/wandb-core for more information.
>>> Tracking run with wandb version 0.19.5
>>> Run data is saved locally in /content/wandb/run-20250131_170132-q9qabdfm
>>> Syncing run DeepSeek-R1-Distill-Qwen-1.5B-fncall_peft-ds_small-lora_r_4-use_qlora_False to Weights & Biases (docs)
>>> [200/200 2:55:15, Epoch 4/5]
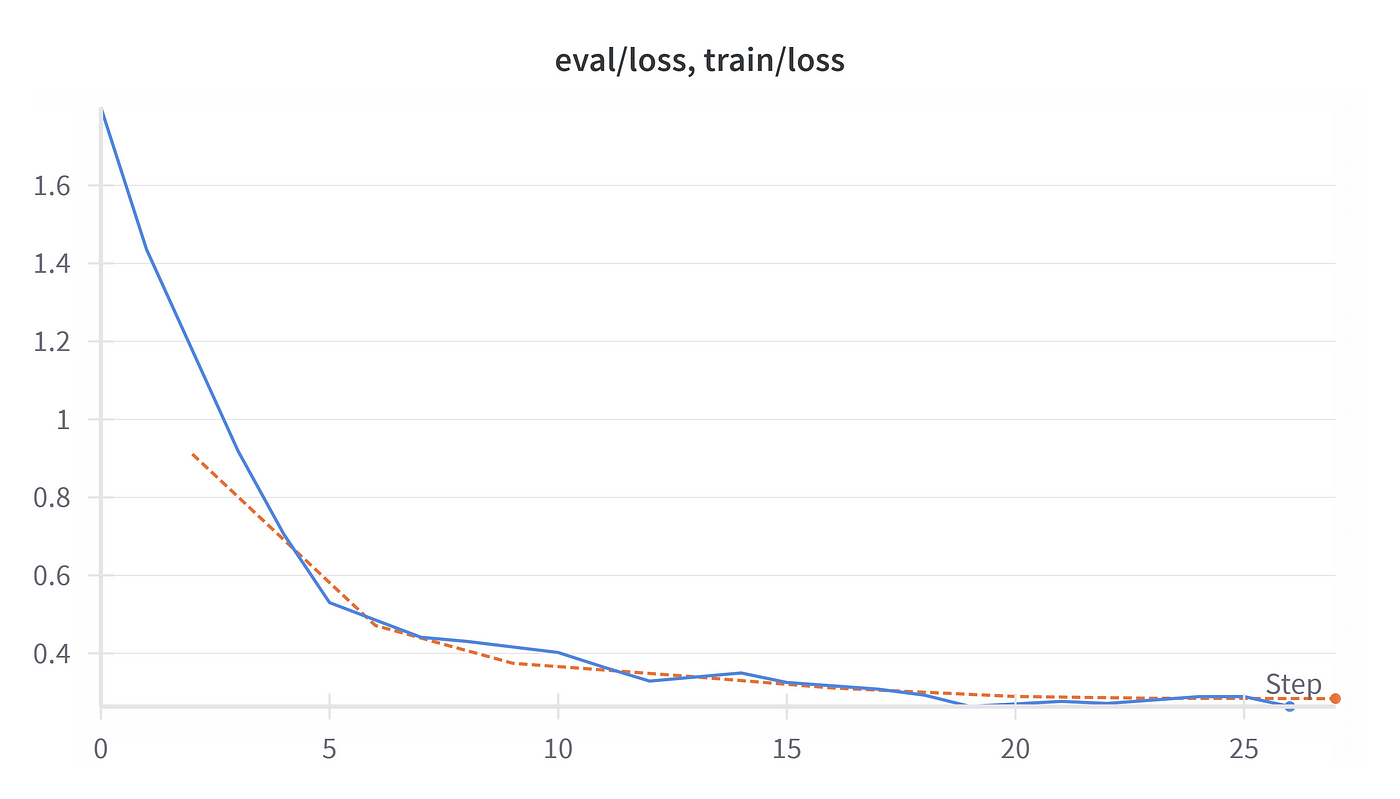
>>> TrainOutput(global_step=200, training_loss=0.5143453764915467, metrics={'train_runtime': 10568.7869, 'train_samples_per_second': 0.303, 'train_steps_per_second': 0.019, 'total_flos': 3.03740523380736e+16, 'train_loss': 0.5143453764915467, 'epoch': 4.444444444444445})With the fine-tuning session done, we can check the results on the Wandb platform and assess how well the system performed during training by checking the validation loss. We can see the model was able to be trained by measuring how validation loss (orange line) decreased over time:
完成微调会话后,我们可以在 Wandb 平台上检查结果,并通过检查验证损失来评估系统在训练期间的表现。我们可以看到,通过测量验证损失(橙线)如何随时间减少,可以训练模型:
**5. Running Inference with the Fine-Tuned Model
5. 使用微调模型运行推理**
After training, load the fine-tune adapters to generate responses from the model.
训练后,加载微调适配器以从模型生成响应。
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Helper function for chat generation.
def run_inout_pipe(chat_interaction, tokenizer, model):
prompt = tokenizer.apply_chat_template(chat_interaction, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=512, pad_token_id=tokenizer.eos_token_id)
outputs = outputs[:, inputs['input_ids'].shape[-1]:]
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# define the model and max_seq_length
max_seq_length = 512
model_name = 'deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B'
# get latest checkpoint from the training sessions
checkpoint_lora_path = 'results/DeepSeek-R1-Distill-Qwen-1.5B-fncall_peft-ds_small-lora_r_4-use_qlora_False/checkpoint-200'
# Load base model and tokenizer.
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="cuda")
tokenizer = AutoTokenizer.from_pretrained(
model_name, padding=True, truncation=True, max_length=max_seq_length
)
offload_dir = "/temp/offload_dir" # In case the model needs to offload weights.
peft_model = PeftModel.from_pretrained(model, checkpoint_lora_path, offload_dir=offload_dir)
chat_interaction = [
{
"role": "system",
"content": '''You are a helpful assistant with access to the following functions. Use them if required -
{
"name": "convert_currency",
"description": "Convert the amount from one currency to another",
"parameters": {
"type": "object",
"properties": {
"amount": {
"type": "number",
"description": "The amount to convert"
},
"from_currency": {
"type": "string",
"description": "The currency to convert from"
},
"to_currency": {
"type": "string",
"description": "The currency to convert to"
}
},
"required": [
"amount",
"from_currency",
"to_currency"
]
}
}'''
},
{
"role": "user",
"content": "Hi, I need to convert 500 US dollars to Euros. Can you help me with that?"
}
]
print(run_inout_pipe(chat_interaction, tokenizer, peft_model))>>> <functioncall> {"name": "convert_currency", "arguments": '{"amount": 500, "from_currency": "USD", "to_currency": "EUR"}'}</functioncall>Conclusion 结论
In this post, we explored how Parameter-Efficient Fine-Tuning via LoRA dramatically reduces the resources needed to adapt LLMs for specific tasks. By injecting low-rank matrices into key layers, only a fraction of the model’s parameters are adjusted while still retaining robust performance.
在这篇文章中,我们探讨了通过 LoRA 的 Parameter-Efficient Fine-Tuning 如何显著减少为特定任务调整 LLM 所需的资源。通过将低秩矩阵注入关键层,只需调整模型参数的一小部分,同时仍保持稳健的性能。


评论 (0)